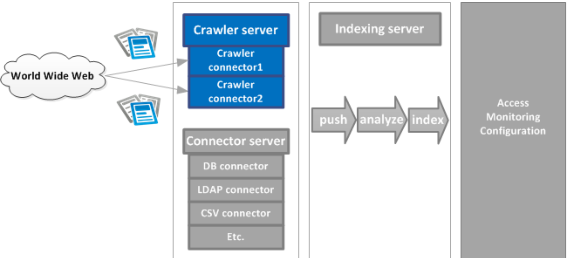
The global connector architecture has two different server processes for hosting the connectors:
• All connectors are hosted by the Connector server
• Except for Crawler connectors that are hosted by the Crawler Server.
The main components of the Crawler architecture are:
• Crawler Server
• Indexing server
Figure 1. Global Crawler Architecture
Crawl Rules
Crawl rules are a set of patterns, matching URLs and assigning actions to them. The most important rules are those which define whether a URL must be crawled, indexed, and whether to follow the links found.
Important: Rule order is critical! All rules are always applied to each URL, starting with the first rule listed. The following rules can potentially override already-applied rules.
Rule Types
When you specify a URL to crawl, you can define two main actions:
• The index rule allows you to index a URL,
• The follow rule allows you to follow its links.
The index and follow rules have their negative counterparts: Don't index and Don't follow.
An ignore rule can completely forbid a URL from being crawled.
Note: The URLs for which no crawl rules are specified, follow the default crawl rules defined in General > Advanced options > Default behavior.
Rule Patterns
Matching can use a wide set of patterns. The most common pattern uses a regular expression on the whole URL string. Other pattern types include many shortcuts, matching only a component of the URL, or comparing a length.
Common patterns include:
• Whole URL prefix
• Host
• Domain
• File extension (suffix of path)
• Query parameter...
The patterns available in the Administration Console are prefixes on entire URLs, supporting regular expressions.
Escaping
To avoid escaping special characters like . and reverse the escaping with .*, use \.\*.
For example, to match all URLs on a site containing a /path/ element, you can use the following pattern: http://www.example.com/\.\*/page/.
Refresh
By default, no refresh is enabled in a new crawler.
There are two modes to refresh crawled documents:
• Smart refresh
• Deterministic refresh
Recommendation: Use the Smart refresh mode. Deterministic refresh is generally only useful when crawling an intranet site with a controlled refresh rate, or when a specific latency is required.
Smart Refresh
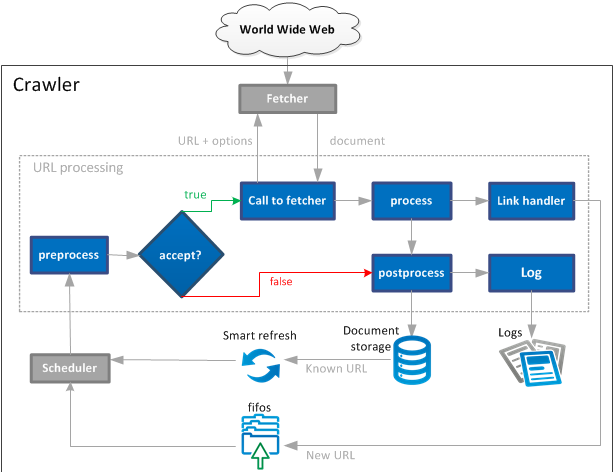
In Smart refresh mode, the crawler picks URLs from its repository depending on their age and update frequency. Fast-changing URLs are refreshed earlier than static ones.
There are two additional parameters: Min and Max age:
• Min age is the age below which a URL is never refreshed,
• and Max age is the age above which a URL is always refreshed.
For example, in the default configuration, a really fast-changing URL is never refreshed faster than every hour, and a completely static page is still refreshed every day.
These parameters assume that the crawler has the available computing and network resources to achieve this refresh, else it will do at best. The Smart Refresh mode is therefore a good choice when you do know the update frequency of documents.
Deterministic Refresh
The Deterministic refresh mode is available through a MAMI command accessible by cvcommand.
Note: For more information about cvcommand, see "Get started with command-line interfaces" in the Exalead CloudView Administration Guide.
The command is called RefreshDocuments and can take two parameters:
• maxAgeS: to select only the URLs that have not been refreshed for a period of time (in seconds),
• prefix: to select only the URLs matching a prefix. This prefix is not a regular expression.
The command extracts all matching URLs from the crawler storage, and adds them in the fifos (the persistent structure containing the URLs to crawl). You can use the product scheduler to run this command periodically.
Note: This refresh can only be guaranteed if the crawler has enough computing and network resources to crawl all refreshed URLs before the next refresh. The number of URLs to refresh on a given host and the crawl delay (2.5 seconds by default) can also limit the refresh rate.
In the following example, the command refreshes all pages that are older than a day on example.com:
[2019/07/11-15:52:34.164] [info] [exa.bee.BeeJob 1127] [crawler.feedfetcher] Refreshing 8756 out of 10000 documents in prefix <http://www.example.com/> [2019/07/11-15:52:38.781] [info] [exa.bee.BeeJob 1127] [crawler.feedfetcher] Refreshing 17216 out of 20000 documents in prefix <http://www.example.com/> [2019/07/11-15:52:49.790] [info] [exa.bee.BeeJob 1127] [crawler.feedfetcher] Refreshing 25782 out of 30000 documents in prefix <http://www.example.com/> ... [2019/07/11-15:54:35.684] [info] [exa.bee.BeeJob 1127] [crawler.feedfetcher] Refreshed 145344 out of 172549 documents in prefix <http://www.example.com/>
Note: In this log, the last message means that the URLs have been scheduled for refresh but are not necessarily refreshed yet.
The URLs to refresh are added to a fifo, by default, it uses the highest priority. See How Priorities Work.
You can check the refresh progress in:
• The Monitoring Console (in <HOST> > Services > Exalead > Connectors > CRAWLER NAME)
• The Crawler connector > Operations & Inspection tab, if you observe the source.0.size crawler probe values.
You can also run a deterministic refresh job periodically (at fixed times, dates or intervals), by editing the <DATADIR>/config/Scheduling.xml file, and specifying a Quartz cron expression. Exalead CloudView executes the MAMI commands defined in this xml file automatically.
In the following example, the refresh_crawler command uses a cron expression that runs the crawler refresh at "0 0 0 * * ?", meaning daily at midnight.
You can specify several schedules by adding as many <TriggerConfigGroup> as required.
<master:SchedulingConfig xmlns="exa:com.exalead.mercury.mami.master.v10"> <master:JobConfigGroup name="refresh_crawlers"> <master:DispatchJobConfig name="refresh_crawler"> <master:DispatchMessage xmlns="exa:exa.bee" messageName="refreshDocuments" serviceName="/mami/crawl"> <master:messageContent> <master:KeyValue key="crawlerName" value="CRAWLERNAME" /> <master:KeyValue key="maxAgeS" value="3600" /> <!-- optional, don't refresh documents younger than 1 hour, else all documents regardless of age --> <master:KeyValue key="prefix" value="URLPREFIX" /> <!-- optional, only refresh documents with URL beginning with prefix, else all documents --> </master:messageContent> </master:DispatchMessage> </master:DispatchJobConfig> </master:JobConfigGroup> <master:TriggerConfigGroup name="exa"> <master:CronTriggerConfig cronExpression="0 0 0 * * ?" misfireInstruction="do_nothing" jobName="refresh_crawler" jobGroupName="refresh_crawlers" name="refresh_crawlers" calendarName="dummy_calendar" /> </master:TriggerConfigGroup> </master:SchedulingConfig>
About Site Collapsing
Often a site does not have a lot of rich content about a specific topic. If a Exalead CloudView user searches for that topic, the search results are overwhelmed with many pages from that site. The result is that other sites with important relevant information get crowded out.
The idea of site collapsing is to treat all the pages from a site as a single page. In this case, Exalead CloudView tries to select the most relevant page from the site, and only shows that one page in the search results. Other sites appear higher in the search results.
Site collapsing works on the assumption that if the page selected to represent the site does not contain the content a user is looking for, there must be enough good links (navigation menus) within the site to allow users to quickly find what they are looking for.
By default, the site collapsing ID is based on the host part of the URL. All URLs belonging to the same host share the same ID and are shown as one collapsed result. You can configure the site ID to include more segments of the URL's path to distinguish sites on the same host. You can do so by specifying the recursion with the Depth parameter. By default, the value is 0, which corresponds to the host part of the URL.
This option pushes a meta called site_id with the documents to index. This meta is based on the site extracted from a URL. To enable site collapsing, you also need to create a group in Search Logics > Sort & Relevance and in the Expression field, enter site_id.
URL Processing
Figure 2. URL Processing in the Crawler
URL Handling of Crawled Sites
The Crawler connector has the following URL handling methods or constraints:
• Only HTTP and HTTPS protocols are accepted.
• Symbolic host names are syntactically checked and converted to lowercase; any trailing periods are removed.
• URL paths are checked for illegal characters (though "unwise" characters are accepted), unreserved characters are unescaped.
• When accepted, URL queries are checked for illegal characters (though "unwise" characters are accepted), unreserved characters are unescaped.
• Escaped characters are printed with lowercase hex digits.
• Fragment identifiers (#part) are checked for illegal characters, then removed.
• Literal IPV4 and IPV6 host names are supported, for example, http://[2001:200:dff:fff1:216:3eff:feb1:44d7]/index.html.