The HTTP Fetcher is the component allowing to download a document from its URL.
The crawler uses it, but also the product's generic fetcher, to generate previews, thumbnails, and direct downloads from the Mashup UI.
The fetcher configuration defined in the Administration Console> CRAWLER connector > Fetcher tab, is also used by the fetchapi remote API, called by the Mashup UI for downloads, thumbnails, and previews.
You can define different fetch configurations. By default, in the Administration Console, each new crawler is associated with a new fetcher configuration.
HTTP Common Parameters
Cookies are always processed, but never stored by default. They are however automatically enabled, stored, and sent back on sites configured with an HTML form authentication. The global Enable cookies for all sites parameter allows you to store and send cookies for all sites. Only cookies following the standard privacy rules are stored, as web browsers do.
The User agent by default identifies itself as a Mozilla-compatible Exalead CloudView. When crawling the public internet, customize it with a URL pointing to a page describing the crawler and how to contact the administrator.
The From field is empty by default, and can contain a contact email address, which is useful when crawling the public internet.
You can add any HTTP header to the default request. The default configuration only contains Accept: */*, which is required by some sites.
Conditional Fetch
The fetcher uses the Last-Modified date and E-Tag HTTP Headers to allow conditional fetch.
The crawler uses this condition when refreshing pages, to avoid fetching unchanged documents. In that case, the server only answers 304 Not Modified.
HTTP Authentication
The fetcher can access pages protected through different kind of authentication protocols.
• Basic only requires a username and a password. They are sent as plain text in the HTTP request.
• Digest requires a username, a password, and an optional realm. Unlike Basic, the Digest protocol avoids sending the password as plain text.
• NTLM requires a username, a password, and either a hostname or a domain.
Configure URL patterns to tell the fetcher which sites the login information applies to. They have the same syntax and meaning that the patterns used in the crawler configuration. They must match only the URLs where the login information is required.
Important: If you do not configure any URL pattern, the authentication applies to all URLs crawled. This can be dangerous, as the password might be sent to a third party.
HTML Form Authentication
The fetcher also supports authentication using HTML forms. This applies to any website where the login procedure involves filling in an HTML form and submitting it through a POST request.
What You Must Know
To properly configure the fetcher to authenticate using an HTML form, gather the following information:
• Find patterns to identify which URLs require authentication. Sometimes authentication is not required or not relevant to retrieve some parts of a website, for example static resources or images. URL patterns are the same than for standard HTTP authentication (see above), and the same recommendations apply. They work the same way as crawl rule patterns, and support the same syntax.
• Describe how to identify a successfully authenticated page from an unauthenticated one. This authentication test requires a success/failure condition, and is applied to all crawled URLs matching the above patterns. You can either choose a characteristic of the failed authentication page, to make a "failure condition", or a characteristic of a successfully authenticated page, to make a "success condition". See below for examples.
• Find the following information to authenticate:
◦ First, find the URL containing the authentication form. This URL is called the gateway URL. It must be unique for the whole site. It is often the URL you are redirected to, when attempting to load a page without being authenticated.
◦ Then, find the authentication form in the HTML. Check, using "view source", that the form is statically embedded in the HTML and not dynamically generated using javascript. In that last case, the fetcher cannot find it. If it is in an iframe, use the iframe URL instead. If the form is not the first one in the page, tell the fetcher how to find the right one: you can use the element's name, id, or class as required. The first matching form is used.
◦ To specify the form input in the fetcher Form fields, you have to find the input name of each required parameter, usually a user name, and a password. In the following input form example, the user field contains the user name, and the passwd field contains the password.
◦ Also check that the login process does not require javascript. In the example above, the action is a relative URL: /login. This is the destination of the POST login request. If it is absent, and the post URL is generated by a javascript method like onSubmit='validateForm();', it is unlikely the fetcher can submit it.
Write a Correct Success/Failure Condition
A good condition must return:
• Failure if and only if the fetch result shows that you are not authenticated.
• Success if and only if the fetch result shows that you have successfully authenticated.
Body text match condition
- Finding a string like Welcome $USER in the content of the page may be a good success criteria.
- Finding a string like Please authenticate to access this document would be a good failure test.
Redirection condition
- The fetcher tests only if a page contains a redirection to another page and does not follow the redirection (a page and its redirection are two different documents).
- Many sites redirect unauthenticated requests to a login page. Assuming the first redirection destination is /login/login.html, a good condition would be Failure if redirection matches /login/login/html.
Matching only the presence of a redirection is usually a bad idea. Sites often contain lots of invisible redirections, even when authenticated.
Warning: Login procedures requiring javascript are not supported, except in the simple case of auto-submitted forms (usually used to transfer cookies or session IDs across domains without setting large query parameters).
Common Misconceptions
• Authentication process and authentication test (the Success/Failure condition) are two independent processes. The authentication test condition is tested every time a document is fetched, but the authentication itself is executed only when the condition returns a failure.
• The crawler and the fetcher are independent. The crawler does not know about authentication. The process is transparent. The fetcher is like a black box, accepting URLs as input and returning authenticated documents. That means that login pages must never be indexed. If it happens, it means that your authentication process is wrong: either the authentication process has failed and the fetcher is not authenticated, or the condition always returns success erroneously (and never triggers the authentication).
• Cookies are automatically enabled and handled, there is no need to enable them manually. Use the Enable cookies for all sites option only if an unauthenticated site requires them.
Cookies are handled transparently by the fetcher. It behaves as much as possible like a standard web browser.
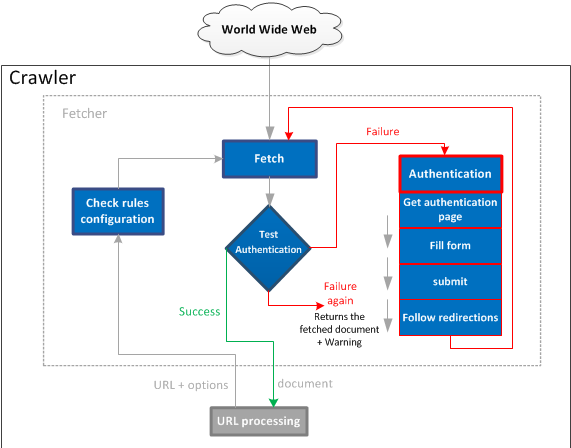
Fetcher Authentication Process
This task shows you how the fetcher performs authentication.
1. The crawler asks the fetcher for a URL. The crawler does not know anything about authentication, and the fetcher does not know anything about the URLs that must be crawled and crawl rules.
2. The fetcher tests whether the URL matches the authentication configuration pattern.
3. The fetcher tries to fetch the URL a first time, without trying the authentication process. If the session has already been opened and is still active, a reauthentication is not required.
4. The fetcher tests the success/failure condition on the fetched document. If the condition returns "success", this means that the page is correctly authenticated, and is returned as is to the crawler.
5. Else, it means that the session has expired and the fetcher has to reauthenticate:
◦ First, it fetches the gateway as configured. It follows redirections as required, until it finds an HTML page.
◦ The login form is extracted from the HTML according to the configuration.
◦ The parameters are extracted from the form, and completed with the username/password fields configured.
◦ The form action is submitted with all these parameters.
◦ Redirections are followed, with a limit to avoid loops. Redirections are often used at this point to transfer authentication tokens to session cookies (which can live on other domains).
6. Finally the fetcher tries to fetch the original URL a second time.
7. The success/failure condition is tested a second time: if the configuration is correct, it returns "success".
8. If the condition is successful, the document is returned to the crawler.
9. Else, the configuration is broken. A warning is printed in the crawler process log, and the resulting document is still returned to the crawler.
Note: process is the process name of your crawler.
2. Click Apply.
3. Look for full HTTP traces in the crawler process log.
Recommendation: This makes the crawler process log really verbose. Do not enable it continuously.
Convert Cookies Files
If everything fails, you can still try to log in with a browser, export the cookies, and give them to the fetcher. This only works until the session expires. For example, with Firefox.
1. Export the cookies.
2. Convert the cookies file with:
sed -e 's#\([^\t]*\)\t\([^\t]*\)\t\([^\t]*\)\t\([^\t]*\)\t\([^\t]*\)\t\ ([^\t]*\)\t\([^\t\n\r]*\)#<HTTPCookie xmlns="exa:exa.net" version="1" name="\6" value="\7" path="\3" domain="\1" secure="false" expires="2099/04/09-11:09:32"/>#' cookies.txt (change the expiry time if necessary).
3. Stop the crawler process.
4. Overwrite the content of the <DATADIR>/fetcher/crawler-INSTANCE/fetcher_CRAWLERNAME/cookies.txt file with the converted cookies.txt file.