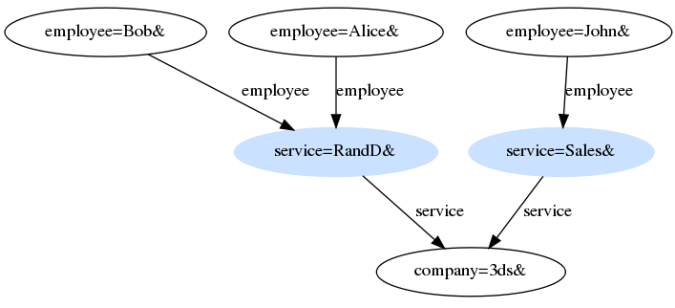
By the following configuration: 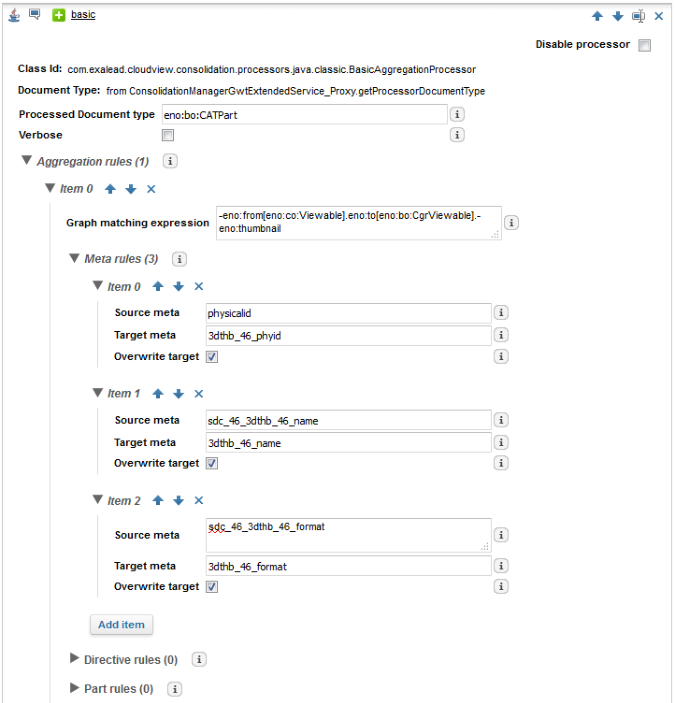
Transformation Processor | Description |
|---|---|
Basic Arc Creation Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. CreateArcBasedOnMetaValueTransformationProcessor Creates an arc from the processed document. The target is the value of the given meta name. |
Basic Document Creation Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. CreateDocumentBasedOnMetaValueTransformationProcessor Creates a managed document from the processed document. The target is the value of the given meta name. |
Set Directive Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. SetDirectiveTransformationProcessor Sets the given directive on the processed document |
Set Meta Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. SetMetaTransformationProcessor Set the given meta on the processed document |
Set Type Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. SetTypeTransformationProcessor Sets the given type on the processed document |
Split Text Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. SplitTextTransformationProcessor Splits the given source meta using the specified delimiting regex pattern, and add/set the result to the target meta. Note: The target meta must be multivalued to contain all text chunks resulting from the split operation. |
Storage Service Key Linker Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. StorageServiceKeyLinkerTransformationProcessor Create arcs between the Storage Service data and the document it is linked to. For a use case example, see UC-8: Consolidating Data from Storage Service. |

Method | Description |
|---|---|
discard() | Discards the current processor document, that is to say, prevents it from going to the next processor or next stage. |
yield(doc) | Yields the newly created document to the next processor or to the Consolidation Store. Use this call for documents created in a transformation processor with the IJavaCreateTransformationHandler methods. |
Method | Description |
|---|---|
createDocument(uri,type,parentTypes) | Creates a transformation document with the required given properties and with automatic memory management. In other words, if no edges point on it at the end of the transformation phase, the document is deleted by the Consolidation Server automatically. |
createChildDocument(parentDoc,subURI,type,parentTypes) | Creates a transformation document from a parent one with the given properties. |
createUnmanagedDocument(uri,type,parentTypes) | Creates a transformation document with the given properties without automatic memory management. This is the opposite behavior of the createDocument method in terms of memory management. |
getDocumentChildrenPath(String parentURI, String childURI) | This method is useful to create a child URI when you do not have access to the child himself. Never forge a URI by hand. |
Method | Description |
|---|---|
deleteDocument() | Sends a recursive delete order for the current document. |
deleteDocument(uri) | Sends a recursive delete order for the document with the given URI prefix. |
deleteDocument(uri,boolean) | Sends a delete order for the specified document URI, recursively or not. If the boolean flag is true, then all URIs with a prefix matching the given URI are also deleted. |
deleteDocument(doc) | Sends a recursive delete order for the specified document and possibly all documents with a prefix matching the document URI. |
deleteDocument(doc,boolean) | Sends a delete order for the specified document, recursively or not. If the boolean flag is true, then all URIs with a prefix matching the document URI are also deleted. |
deleteDocumentChildren(doc,path) | Sends a delete order for all document children matching the given path. The document itself is not deleted. |
deleteDocumentChildren(doc) | Sends a delete order for all document children. The document itself is not deleted. |
deleteDocumentChildren(parentURI,path) | Sends a deletion order for all document children matching the path of the given parent URI. The document itself is not deleted. |
deleteDocumentChildren(parentURI) | Sends a deletion order for all document children with the given parent URI prefix. The document itself is not deleted. |
deleteDocumentRootPath(rootURI) | Sends a deletion order for all documents matching the root URI prefix. |
Method | Description |
|---|---|
addArcFrom(arcType, fromDoc) | Registers an arc addition from the specified document to the current one. |
addArcFrom(arcType, fromDocURI) | Registers an arc addition from the document specified by the URI to the current one. |
addArcTo(arcType, toDoc) | Registers an arc addition from the current document to the specified document. |
addArcTo(arcType, toDocURI) | Registers an arc addition from the current document to the document specified by the URI. |
removeAllPredecessorArcs() | Registers for deletion all adjacent arcs heading to the current one. |
removeAllSuccessorArcs() | Registers for deletion all adjacent arcs starting from the current one. |
removeArcFrom(arcType, fromDoc) | Registers for deletion the arc starting from the specified document to the current one, with the given type. |
removeArcFrom(arcType, fromDocURI) | Registers for deletion the arc starting from the specified document to the current one, with the given type. |
removeArcTo(arcType, toDoc) | Registers for deletion the arc starting from the current document to the specified document, with the given type. |
removeArcTo(arcType, toDocURI) | Registers for deletion the arc starting from the document specified by the URI to the current one, with the give type. |
setType(documentType, parentTypes) | Defines the document type, as well as its possible parents as defined in getTypeInheritance(). |
Method | Description |
|---|---|
isOfType(type) | Indicates if the type transmitted is among the list of the current document types. |
getAllDirectives() | Returns all the directives defined in this document. |
getAllMetas() | Returns all the metas defined in this document. |
getAllParts() | Returns all the parts defined in this document. |
getDirectiveNames() | Returns all the document directive names. |
getDirective(name) | Returns the first directive value for the given name. |
getDirectives(name) | Returns all the directives for the given name. |
getMetaNames() | Returns all the meta names. |
getMeta(name) | Returns the first meta value for the given name. |
getMetas(name) | Returns all the meta values for the given name. |
getOriginalSources() | Returns the list of original sources for the given document. |
getPartNames() | Returns all the document part names. |
getPart(name) | Returns the first document part for the given name. |
getParts(name) | Returns the list of document parts for the given name. |
getSource() | Returns the document original source that produced it. |
getType() | Returns the document representative type. |
getTypeInheritance() | Returns the type inheritance for the document. The first one in the list is a descendant of the second one, the second one of the third one, and so on. So types are ordered from the most specific to the most generic. |
getUri() | Returns the document unique identifier. |
hasDirective(name) | Indicates if the directive name has an associated value within the document. |
hasMeta(name) | Indicates if the meta name has an associated value within the document. |
hasPart(name) | Indicates if the part name has an associated value within the document. |
Method | Description |
|---|---|
deleteDirective(name) | Deletes all the directive values associated to the specified directive name. |
deleteDirectives(name, values) | Deletes only the given values for the specified directive name. |
deleteMeta(name) | Deletes all the meta values associated to the specified meta name. |
deleteMetas(name, values) | Deletes only the given meta values from the specified meta name. |
deleteParts(name) | Deletes the document parts related to the specified part name. |
deleteParts(name, documentParts) | Deletes all the part directive values for the specified part name. |
setDirective(name, value) | Assigns the given value to the specified directive name. |
setAllDirectives(directives) | Assigns all the directive name/values associated to the current document. |
setMeta(name, value) | Assigns the given meta value to the specified meta name. |
setMeta(name, values) | Assigns the given meta values to the specified meta name. |
setAllMetas(metas) | Assigns all the meta name/values associated to the current document. |
setPart(name, docPart) | Assigns the given document part to the specified part name. |
setParts(name, docParts) | Assigns the given document parts to the specified part name. |
setAllParts(parts) | Assigns all the parts associated to the current document. |
withDirective(name, value) | Adds the value of a specific directive to the possible list of predefined directive values. If none is defined, a new list is created. |
withDirectives(name, values) | Adds the values of a specific directive to the possible list of predefined directive values. If none is defined, a new list is created. |
withDirectives(directives) | Adds the list of directive key-values to the possible list of predefined directive values. |
withMeta(name, value) | Adds the value of a specific meta to the possible list of predefined meta values. If none is defined, a new list is created. |
withMeta(name, values) | Adds the values of a specific meta to the possible list of predefined meta values. If none is defined, a new list is created. |
withMetas(metas) | Adds the list of meta key-values to the possible list of predefined meta values. |
withPart(name, docPart) | Adds the document part to the list of existing predefined parts. If none is defined, a new list is created. |
withPart(name, docParts) | Adds the sequence of document parts to the list of existing predefined parts. If none is defined, a new list is created. |
withParts(allParts) | Adds the list of parts associated to the current document. |
Aggregation Processor | Description |
|---|---|
Basic Aggregation Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. BasicAggregationProcessor Add/set metas, directives, or parts from documents at the end of paths, returned by the given graph matching expression. See the example below this table. |
Classification Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. ClassficationAggregationProcessor Generates classification metadata representing path nodes ('node1_id/node2_id/node3_id...') |
Discard Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. DiscardAggregationProcessor Discards documents matching the given document types. For a use case example, see UC-8: Consolidating Data from Storage Service. |
Set Directive Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. SetDirectiveAggregationProcessor Sets the given directive on the processed document. |
Set Meta Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. SetMetaAggregationProcessor Sets the given meta on the processed document. |
Storage Service Key Flattener Processor | Class Id: com.exalead.cloudview.consolidation.processors.java.classic. StorageServiceKeyFlattenerAggregationProcessor Sets metas on a document coming from the Storage Service. For a use case example, see UC-8: Consolidating Data from Storage Service. |
Interconnector Aggregator Processor | Class Id: com.exalead.cloudview.consolidation.processors.java. InterconnectorAggregatorProcessor Aggregates a parent document with its child document, given a graph path from parent to child. For a use case example, see in the Exalead CloudView Connectors Guide. |
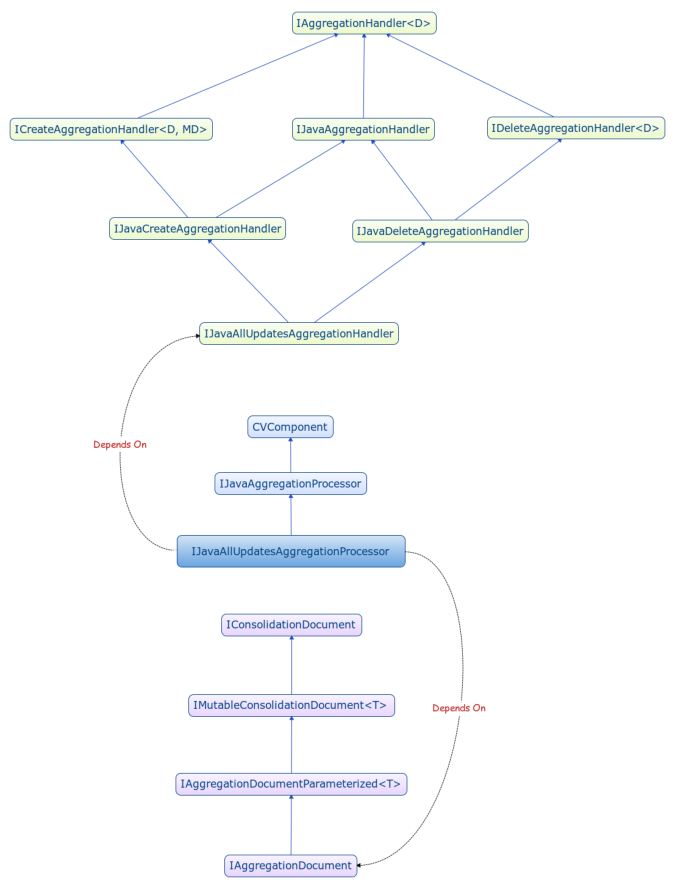
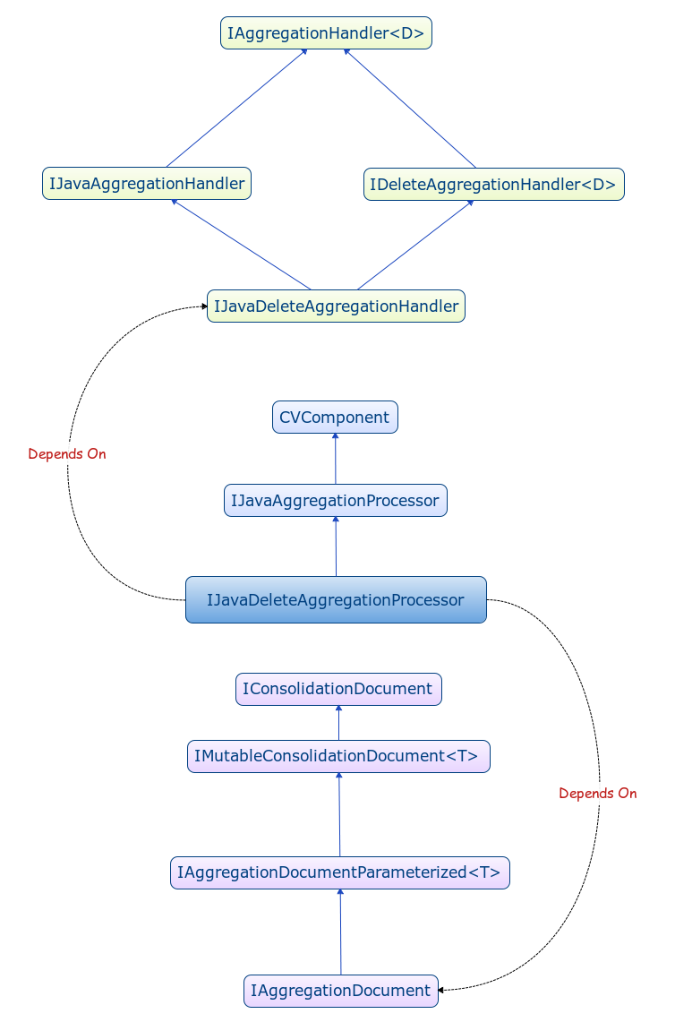
Method | Description |
|---|---|
discard() | Discards the current processor document, that is to say, prevent it from going to the next processor or next stage. |
getReason() | Returns a string representing the reason why the document is pushed to aggregation. It can have one of the following values: ADDED, DELETED, IMPACTED. |
match(doc,graphMatchingExpression) | Finds the list of paths in the graph that start from the specified IAggregationDocument and that satisfy the graphMatchingExpression. Returns them as a list of documents. |
matchPathEnd(doc,graphMatchingExpression) | Finds the documents at the end of each path in the graph, that starts from the specified IAggregationDocument and that satisfy the graphMatchingExpression. Returns them as a list of documents. This is useful when you do not want to overload the Consolidation Server with a lot of useless intermediary documents, found on the path between the starting document and the document level you chose as path end. In other words, instead of considering all the vertices on a given path, it only considers the one at the end. |
matchPathEnd(doc,graphMatchingExpression,metas) | Finds the documents at the end of each path in the graph, that starts from the specified IAggregationDocument, satisfy the graphMatchingExpression. Returns them as a list of documents. The goal of this method is to avoid impacting elements if the meta that changed is not used. Instead of considering all the vertices on a given path, it only considers the one at the end, only if the meta used has changed. This is triggered when the impact detection is launched during the incremental scan. Warning: This method does not work with Date metas. |
matchPathEnd(doc,graphMatchingExpression, testDirectives,testParts,metas) | Finds the documents at the end of each path in the graph, that starts from the specified IAggregationDocument, satisfy the graphMatchingExpression. Returns them as a list of documents. The goal of this method is to avoid impacting elements if the meta that changed is not used, and if directives and parts are the same. Instead of considering all the vertices on a given path, it only considers the one at the end, only if the meta used has changed, or if directives are different, or if parts are different. This is triggered when the impact detection is launched during the incremental scan. Warning: This method does not work with Date metas. |
yield(doc) | Yields the newly created document to the forward rules without passing through the whole pipeline of aggregation processors. Use this call for documents created in an aggregation processor with the IJavaCreateAggregationHandler methods. |
yieldAndForward(doc) | Yields the documents newly created in an aggregation processor to the next aggregation processor in the pipeline of aggregation processors. Use this call for documents created in an aggregation processor with the createDocument or the createChildDocument methods. This is to make sure that the document is forwarded to the next processor and not sent to the specified forward rules directly, unlike the yield(doc) method. |
Method | Description |
|---|---|
match(doc,graphMatchingExpression,matchResultVisitor) | Finds the list of paths in the graph that start from the specified IAggregationDocument and that satisfy the graphMatchingExpression. Unlike the other match method, it provides the results using the matchResultVisitor instance with all unique documents matching the graph matching expression (independently of the paths reached). |
Method | Description |
|---|---|
createDocument(uri,type,parentTypes) | Create an aggregation document with the given properties. Unlike ICreateTransformationHandler.createDocument, this document is not automatically deleted if there are no edges point on it at the end of the aggregation phase. It is pushed as is to the forward rules, and sent (or not) to an Indexing Server or another Consolidation Instance. |
createChildDocument(parentDoc,subURI,type,parentTypes) | Creates an aggregation document from a parent one with the given properties. |
isFetchOperation() | When a Fetch Server performs a fetch operation request to the Consolidation Server, this handler (and in this case only) returns true. When this is the case, all the aggregation operations performed in the processor are directed in return to the Fetch Server. None of the documents aggregated proceed to the forward rules handler, and thus to the Indexing Server. The operations allowed in such event are the ones of a create/update context, and the fetchParts operation. In most cases, you do not have to deal with this kind of situation. |
fetchParts(document,connectorName, connectorDocumentURI) | Fetches the parts corresponding to the connectorDocumentURI document from the connector specified by connectorName and appends them to the given document. This call makes sense only when the isFetchOperation() method returns true. |
Method | Description |
|---|---|
deleteDocument() | Sends a recursive deletion order for the document being aggregated, and all the other documents with a prefix matching the current document URI. |
deleteDocument(docTypes...) | Sends a recursive deletion order for the document being aggregated, and all the other subdocuments with a prefix matching the current document URI. Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a recursive deletion order is sent for the specified document types matching the current document URI. |
deleteDocument(uri,boolean) | Sends a deletion order for the specified document URI, recursively or not. If the boolean flag is true, then all URIs with a prefix matching the given URI are also deleted. |
deleteDocument(uri, docTypes...) | Sends a recursive deletion order for the document with the specified URI prefix. |
deleteDocument(uri,boolean,docTypes...) | Sends a deletion order for the specified document URI, recursively or not. If the boolean flag is true, then all URIs with a prefix matching the given URI are also deleted. Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a deletion order (recursive or not) is sent for the given document types matching the specified document URI. |
deleteDocument(doc) | Sends a recursive deletion order for the specified aggregated document and possibly all documents with a prefix matching the document URI. |
deleteDocument(doc,docTypes...) | Sends a recursive deletion order for the specified aggregated document and possibly all documents with a prefix matching the document URI. Moreover, a recursive deletion order with the given document is sent with the additional forward rule types provided, to delete documents not recognized in the Consolidation Store while allowing correct routing/filtering by the forward rules handler (if required). Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a recursive deletion order is sent for the given document types matching the current document URI. |
deleteDocument(doc,boolean) | Sends a deletion order for the given document, recursively or not. If the boolean flag is true, then all URIs with a prefix matching the document URI are also deleted. |
deleteDocument(doc,boolean,docTypes...) | Sends a deletion order for the given document, recursive or not. If the boolean flag is true, then all URIs with a prefix matching the document URI are also deleted. Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a deletion order (recursive or not) is sent for the specified document types matching the document URI. |
deleteDocumentChildren(doc,path) | Sends a deletion order for all document children matching the given path. The document itself is not deleted. |
deleteDocumentChildren(doc,path,docTypes...) | Sends a deletion order for all document children matching the given path. The document itself is not deleted. Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a recursive children deletion order is sent for the specified document types matching the current document URI. |
deleteDocumentChildren(uri,path) | Sends a deletion order for all document children of the given URI matching the given path. The document itself is not deleted. |
deleteDocumentChildren(uri,path,docTypes...) | Sends a deletion order for all document children of the given URI matching the given path. The document itself is not deleted. Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a recursive children deletion order is sent for the specified document types matching the specified document URI. |
deleteDocumentChildren(doc) | Sends a deletion order for all document children. The document itself is not deleted. |
deleteDocumentChildren(doc,docTypes...) | Sends a deletion order for all document children. The document itself is not deleted. Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a recursive children deletion order is sent for the specified document types matching the current document URI. |
deleteDocumentChildren(uri) | Sends a deletion order for all document children of the given URI. The document itself is not deleted. |
deleteDocumentChildren(uri,docTypes...) | Sends a deletion order for all document children of the given URI. The document itself is not deleted. Moreover, to delete documents not recognized in the Consolidation Store and allow correct routing/filtering by the forward rules handler, a recursive children deletion order is sent for the specified document types matching the specified document URI. |
deleteDocumentRootPath(rootURI) | Deletes all the documents matching the root URI prefix. |
deleteDocumentRootPath(rootURI,docTypes...) | Deletes all the documents matching the root URI prefix, and with some forward rule types to allow correct routing/filtering by the forward rules handler. |
Method | Description |
|---|---|
isOfType(type) | Indicates if the type transmitted is among the list of the current document types. |
getAllDirectives() | Returns all the directives defined in this document. |
getAllMetas() | Returns all the metas defined in this document. |
getAllParts() | Returns all the parts defined in this document. |
getDirectiveNames() | Returns all the document directive names. |
getDirective(name) | Returns the first directive value for the given name. |
getDirectives(name) | Returns all the directives for the given name. |
getMetaNames() | Returns all the meta names. |
getMeta(name) | Returns the first meta value for the given name. |
getMetas(name) | Returns all the meta values for the given name. |
getOriginalSources() | Returns the list of original sources for the given document. |
getPartNames() | Returns all the document part names. |
getPart(name) | Returns the first document part for the given name. |
getParts(name) | Returns the list of document parts for the given name. |
getSource() | Returns the document original source that produced it. |
getType() | Returns the document representative type. |
getTypeInheritance() | Returns the type inheritance for the document. The first one in the list is a descendant of the second one, the second one of the third one, and so on. So types are ordered from the most specific to the most generic. |
getUri() | Returns the document unique identifier. |
hasDirective(name) | Indicates if the directive name has an associated value within the document. |
hasMeta(name) | Indicates if the meta name has an associated value within the document. |
hasPart(name) | Indicates if the part name has an associated value within the document. |
Method | Description |
|---|---|
deleteDirective(name) | Deletes all the directive values associated to the specified directive name. |
deleteDirectives(name, values) | Deletes only the given values for the specified directive name. |
deleteMeta(name) | Deletes all the meta values associated to the specified meta name. |
deleteMetas(name, values) | Deletes only the given meta values from the specified meta name. |
deleteParts(name) | Deletes the document parts related to the specified part name. |
deleteParts(name, documentParts) | Deletes all the part directive values for the specified part name. |
setDirective(name, value) | Assigns the given value to the specified directive name. |
setAllDirectives(directives) | Assigns all the directive name/values associated to the current document. |
setMeta(name, value) | Assigns the given meta value to the specified meta name. |
setMeta(name, values) | Assigns the given meta values to the specified meta name. |
setAllMetas(metas) | Assigns all the meta name/values associated to the current document. |
setPart(name, docPart) | Assigns the given document part to the specified part name. |
setParts(name, docParts) | Assigns the given document parts to the specified part name. |
setAllParts(parts) | Assigns all the parts associated to the current document. |
withDirective(name, value) | Adds the value of a specific directive to the possible list of predefined directive values. If none is defined, a new list is created. |
withDirectives(name, values) | Adds the values of a specific directive to the possible list of predefined directive values. If none is defined, a new list is created. |
withDirectives(directives) | Adds the list of directive key-values to the possible list of predefined directive values. |
withMeta(name, value) | Adds the value of a specific meta to the possible list of predefined meta values. If none is defined, a new list is created. |
withMeta(name, values) | Adds the values of a specific meta to the possible list of predefined meta values. If none is defined, a new list is created. |
withMetas(metas) | Adds the list of meta key-values to the possible list of predefined meta values. |
withPart(name, docPart) | Adds the document part to the list of existing predefined parts. If none is defined, a new list is created. |
withPart(name, docParts) | Adds the sequence of document parts to the list of existing predefined parts. If none is defined, a new list is created. |
withParts(allParts) | Adds the list of parts associated to the current document. |