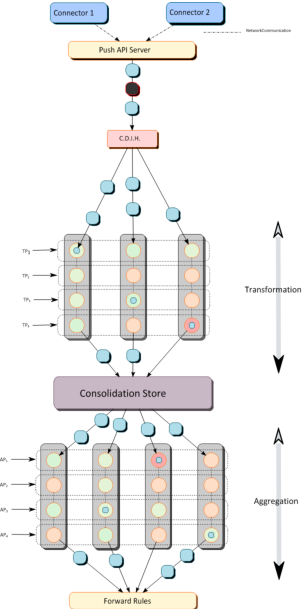
The following diagram gives a detailed view of document processing in the Consolidation Server.
At the top level, connectors send documents to the Consolidation Server. The PushAPI Server receives them and first pass them to the Consolidated Document Identifier Holder (CDIH), which assigns them unique IDs.
Note: If we send a delete order for a particular document that the CDIH does not know, the order does not even proceed to the transformation processors. This is the case for the document depicted in black in the picture.
For each transformation thread, the PushAPI Server then dispatches them to a list of transformation threads. In the processing chain of one transformation thread, a document tries to be applied on all defined processors (here 4 in the diagram, 1 <= TPi <= 4). We say "try" since, as we will see later, you can associate a processor code to a particular document type hierarchy. As a result, some processors are skipped (colored in orange) and others are selected (colored in green) depending on the document type. For more information, see Processor Type Inheritance and Runtime Selection.
At execution time, once the document is transmitted to a transformation processor, it is then automatically passed to the next available and valid processor... unless told otherwise (using a discard call). This the case, for example, for the processor highlighted in red where the document is not transmitted to the next phase (either next processor or here the Consolidation Store). Clearly when making such decision, this document does not participate to the Aggregation Phase.
The Consolidation Store stores all the documents pushed to it as well as the potential relationships created at the transformation phase.
Once some documents are available in the Store, the aggregation phase can start, independently of the transformation phase. So, the transformation and aggregation phases are performed in parallel. And similarly to the transformation phase, the aggregation is concurrently applied using a number of threads defined at configuration time. The logic of selection and processing is then totally similar to the one described for the transformation. The difference is that in this phase:
1. We execute aggregation processors (here 4, 1 <= APi <= 4),
2. Then documents are passed to the forward rules handler,
3. The forward rules handler ultimately route (or not) consolidated documents to the Indexing Servers or to other Consolidation Servers.
Processor Action Context
You have to define an action context for each processor in the Consolidation Server pipeline.
There are two different action contexts to specify the action performed on documents:
• create/update: to create or update documents coming from one or more connectors or the Consolidation Store.
• delete: to delete documents from the connectors or the Consolidation Store.
Delete Action Context
This is what occurs in the Consolidation Server when connectors push delete orders to remove documents from the Indexing Server:
• If you defined a processor with a delete action context that matches the document types, the processor code is executed and yields to the next processor or stage, unless a discard operation is specified.
• If you did not define a processor with a delete action context, or if it does not match the document types, the document proceeds as if a default processor was defined with auto-yielding. This behavior is true for both transformation and aggregation phases.
In other words, unless a delete processor has been defined and matches the document types, when connectors push delete orders, the Consolidation Server:
1. Pushes a delete order to the Consolidation Store and removes documents from it.
2. Pushes delete orders to the Indexing Servers and removes them from the Indexing Store.
In addition, default delete orders are also applied to all child documents.
Delete Orders in Create/Update Action Context
You can also perform delete orders in a create/update action context, using deleteDocument operations. This is mostly in the Aggregation Phase that such operations can be useful. Indeed, we recommend controlling the presence of documents in the Consolidation Store with orders coming from the connectors.
Control the Processing
In Java and Groovy, the evaluation of documents in the list of transformation and aggregation processors is:
• Ordered: They are processed in the order they are defined.
• Automatic: Processed documents are allowed to pass to the next processor or the next stage automatically without declaring a yield operation. However, you must yield explicitly all documents created inside a processor. Calls to delete operations are automatically yielded.
Since the document is automatically passed to the next processor or the next stage available in the processing pipeline, you must make a call to the discard method to prevent it from going further.
This method stops the pipelining. If the document was already present in the Consolidation Store, discarding it at the transformation phase does not delete it from the Consolidation Store. If you want to discard it and ask for deletion, you can add a delete operation in the processor where the discard operation occurs.
Important: As for the yield method, the discard method does not interrupt the runtime execution flow of your processor.
In the following code snippet, the code after discard is executed. If you want to interrupt the flow, you have to add a return; after the discard call. The documents to yield in an aggregation processor are the current processed document and, potentially the documents created during the process code execution.
Recommendation: Do not yield other documents that could have been grabbed using a match function. Doing so would lead to undefined behavior on the receiving end (Indexing Server for example).
@Override public void process(final IJavaAllUpdatesAggregationHandler handler, final IAggregationDocument document) throws Exception { ... if (someCondition) { ... discard(); } // Some other calls ... }
Every document, within the transformation or aggregation phase, has at least one type, but possibly more. You can define a type inheritance for each of them.
To do so, see: IMutableTransformationDocumentParameterized.setType, ICreateTransformationHandler.create'*', ICreateAggregateHandler.create'*'.
For example, you could write:
@Override public void process(final IJavaAllUpdatesTransformationHandler handler, final IMutableTransformationDocument document) throws Exception { document.setType("cat", "felid", "mamal", "vertebrate"); ... }
As a result, the processors selected for execution apply the following rules:
• Either the transformation or aggregation has the all types pattern.
◦ In Java, this is achieved by returning null or an empty string.
◦ In Groovy, this is achieved with an empty string.
• Or the document type inheritance matches the defined processor type.
With the following sequence of Groovy aggregation processors, the document presented before is executed in order within Processor 1, Processor 3, and Processor 4.