Tokenization is the process of splitting up a segment of text into smaller pieces, or tokens. Tokens can be broadly described as words, but it is more accurate to say that a token is a sequence of characters grouped together for useful semantic processing.
Since tokenization is a required processing step for all searchable alphanumeric text, it is set up automatically as part of the Exalead CloudView installation. This setup is known as the default tokenization config, tok0.
A tokenization configuration specifies which tokenizers to use when Exalead CloudView analyzes incoming documents at index-time. It also specifies how to tokenize queries at search-time.
Note: You can test the result of the tokenization process in Index > Data Processing> Test.
Cloudview tokenizes many languages natively. This is the Standard support.
Standard tokenizer
This tokenizer is set up by default when you install Exalead CloudView. It breaks down text into tokens whenever it encounters a space or a punctuation mark. It recognizes all known punctuation marks for all languages.
You can have either:
• One Standard tokenizer, to process all languages without a dedicated tokenizer (this is the default setup).
• Multiple Standard tokenizers to process one or several specified languages for which you want to guarantee a certain tokenization behavior.
Character Overrides
When Exalead CloudView tokenizes text, it examines each character and checks the character override rules for any special processing instructions for this particular character.
Type
Description
token (default)
Processes the specified character as a normal alphanumeric character.
ignore
Does not process the specified character during indexing, and does not include it when building the query tree at search time.
punct
Processes the specified character as a punctuation mark.
Important: The underscore character is not considered as a punctuation mark by default. For example, john_doe is considered as a single token. To consider the underscore as a punctuation mark, specify it in the characters to override (_). For example, john_doe is sliced into three tokens.
sentence
The specified character denotes the end of a sentence.
separator
Processes the specified character as a separator.
Pattern Overrides
WhenExalead CloudView tokenizes text, it searches for any patterns between the current location to the end of the document, based on the pattern override rules. For each matching pattern, it applies the corresponding processing instruction to this particular pattern.
Specify patterns using PERL 5 regular expressions.
Type
Description
token (default)
Processes the specified pattern as a normal alphanumeric pattern.
The following override patterns are used for standard tokenization:
[[:alnum:]][&][[:alnum:]] – for example, M&M or 3&c are considered as one token.
[[:alnum:]]*[.](?i:net) – none, one or several alphanumeric characters followed by .net or .Net or .NET or .nEt or .nET or .neT is considered as a single token, for example, .Net, ASP.NET
[[:alnum:]]+[+]+ – for example, C++ is considered as one token.
[[:alnum:]]+# – one or several alphanumeric characters followed by a sharp sign are considered as a single token, for example, M#, free#, 2u#
Example: to avoid slicing compound words separated by hyphens into 3 tokens and get only one token, you can set the following pattern:
[[:alnum:]]+[-][[:alnum:]]+
ignore
Does not process the specified pattern during indexing, and does not include it when building the query tree at search time.
punct
Processes the specified pattern as a punctuation mark.
sentence
The specified pattern denotes the end of a sentence.
separator
Processes the specified pattern as a separator.
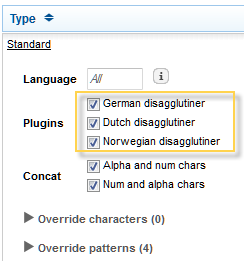
Disagglutination Options
Selecting these options for German, Norwegian, or Dutch means once the tokenizer has produced a token during indexing, it checks if the token is a compound word. If it is, it adds annotations for each part of the compound word. This way, searching for one part of the compound word can match the whole word.
Selecting these options ensures words that include numbers are processed as a single token. For example:
• Windows7 is processed as a single token if concatAlphaNum is true. Otherwise, it is processed as two tokens.
• 9Mile is tokenized as a single token if concateNumAlpha is true. Otherwise, it is processed as two tokens.
Normal separator rules for tokenization still apply: if there is a separator between numbers and other letters, the numbers and letters are processed as two separate tokens.
Transliteration Option
You can activate the transliteration option in the Exalead CloudView XML configuration (it is not available in the Administration Console), for transliterating Unicode Latin Extended B characters. Several characters are converted to their closest Latin equivalent to facilitate query typing. This is useful when you want to match documents in another charset from the one you use for searching.
For example, you may want to search for words containing "Ł" using the closest Latin character "L" even though it does not match phonetically.
As for now, the supported transliterations are the following:
• 00D0 = Ð -> 'd'
• 0110 = Đ -> 'd'
• 00F0 = ð -> 'd'
• 0111 = đ -> 'd'
• 00D8 = Ø -> 'o'
• 00F8 = ø -> 'o'
• 0126 = Ħ -> 'h'
• 0127 = ħ -> 'h'
• 0131 = ı -> 'i'
• 0141 = Ł -> 'l'
• 0142 = ł -> 'l'
• 0166 = Ŧ -> 't'
• 0167 = ŧ -> 't'
• 0192 = ƒ -> 'f'
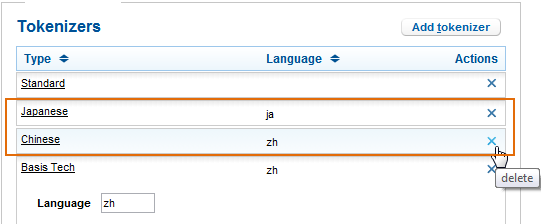
Japanese Tokenizer
This tokenizer is set up by default. You can have only one Japanese tokenizer per tokenization config.
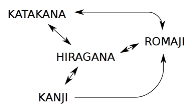
The 4 alphabets used in Japanese texts (kanji, hiragana, katakana, romaji) are implemented by this tokenizer.
Japanese Text Normalization
The text normalization process for Japanese is more complex than for European languages:
• normalization of half-width katakana to full-width, applying NFKC (Normalization Form Compatibility Composition)
• normalization of full-width roman characters to standard latin alphabet
• in addition to each normalized token, indexing of the corresponding hiragana form. At query time, the same processing is applied. It allows to match this normal form with the alphabet used in the documents and the query.
• over-indexing of the okurigana-free forms of kanji
This processor supports the following transcriptions:
The default configuration uses only tokens and their hiragana transcriptions. You can use any processor in the semantic pipe to exploit other transcriptions produced for linguistic purposes. To annotate text with parts of speech to flag nouns, verbs, and adjectives, select the option Add morphology in Linguistics > Tokenizations > your tokenization > Japanese.
Use of Recall
Since tokenizing japanese text is a difficult task, the processor may produce different outputs for the same input. Some of them may contain errors.
For example, in the following cases, queries may fail and skip documents (thus increasing silence):
• the context is different.
A text may be tokenized in the context of a document in a different way than it is in a query because the context is missing.
• the alphabet is different.
For example, tokenizing kanji may produce a different output than tokenizing the equivalent hiragana.
• the document has been processed by a nonjapanese tokenizer at indexing time.
For example, the tokenizer for european languages produces single-character tokens from japanese texts, which do not match correct japanese tokenization.
To maximize recall and avoid errors, a character-based over-indexing is enabled by default. This over-indexing reduces search silence by trying to match character sequences independently of tokenization, in addition to the tokenized query. However, to avoid an unreasonable amount of noise in top search results, this character-based query expansion has a much lower contribution to the document score than the tokenized part.
If too many results are displayed, you can disable this recall by changing the value of the favor option from recall to precision in the Japanese tokenizer configuration (in <DATADIR>/config/Linguistic.xml).
Japanese Spell-Check Settings
To compute spell-check suggestions for Japanese, you need to change default settings in Search > Search logics > Your search logic > Query Expansion. See Set Up Spell-Check for CJK (Chinese-Japanese-Korean) for more details.
If you have purchased Extended Languages, you can remove this tokenizer and instead set up a Basis Tech tokenizer for Japanese tokenization.
The main differences are:
• Exalead tokenizer is based on the open-source JUMAN Japanese processor. BasisTech is based on proprietary technology. You may find differences in tokenization results when switching from one system to another.
• Exalead tokenizer shows better processing performances on average.
• BasisTech tokenizer shows a higher coverage when extracting named entities.
Chinese Tokenizer
This tokenizer is specified by default. You can only have one Chinese tokenizer per tokenization config.
It includes the option to annotate the text with simplified Chinese transliterations.
The Chinese tokenizer retrieves first (and with a higher score) the sets of ideograms that correspond to real words. It also tokenizes ideogram by ideogram to support arbitrary ideogram combination, but this is less relevant in terms of meaning.
Note: If you have purchased Extended Languages, you can remove this tokenizer and instead set up a Basis Tech tokenizer for Chinese tokenization.
Using Basis Tech Tokenizer
Exalead CloudView also offers Extended Languages, provided by a third-party linguistic platform, Basis Technology’s Rosette. Basis Tech is only available if you have installed the Extended Languages add-on.
You can define a Basis Tech tokenizer for a specific language only. Basis Tech tokenizers generally offer richer semantic processing for Asian, Middle-eastern, and African languages than the native Exalead CloudView tokenizers.
Note: For the complete list of supported languages, see the "CloudView Supported Languages" datasheet.
Install the Extended Languages Add-On
This gives you access to the Basis Tech tokenizer. This add-on is available as a separate license.
1. See "Install add-ons" in the Exalead CloudView Administration Guide.
a. From the Administration Console, go to Help > License.
b. Check that the Extended Languages feature is available.
Enable Extended Languages
Create one Basis Tech tokenizer for each language to be tokenized.
Important: There are additional steps for setting up Basis Tech tokenizers for Chinese, Japanese, German, Dutch, or Norwegian. See steps 5 and 6.
Before enabling Extended Languages, keep in mind the following:
• While providing more in-depth text analysis for certain languages, Basis Technology’s analysis typically requires more RAM.
• Named Entities extraction for languages with Extended Languages enabled are determined by Basis Technology’s tokenization rules instead of Exalead CloudView’s:
Basis Technology uses a tokenization based on the Unicode standard word boundaries definition () with a few customizations.
The main difference with Exalead CloudView's tokenization is that Basis Tech tokenization does not split text on certain punctuation when they are not preceded and followed by blank spaces.
◦ colons: Basis Tech keeps together 12:30pm. Standard tokenization produces three tokens 12 + : + 30pm
◦ periods: I.B.M. or 12.33 both produce a single token
◦ apostrophes: a single token for can't or 1970's
This may affect your downstream processing in the semantic pipeline. For example, when an ontology has been compiled with Exalead CloudView's default tokenization, terms made of those characters do not match.
1. In the Administration Console, go to Index > Linguistics > Tokenizations.
2. Click your tokenization config (for example, tok0).
3. In Tokenizers, click Add tokenizer.
a. For Type, select Basis Tech, and then click Accept.
b. For Language, select the language to tokenize.
4. Repeat the previous step for each language you want to tokenize.
5. If adding Basis Tech tokenizers for Japanese or Chinese, delete the default Exalead Japanese and Chinese tokenizers
6. If adding Basic Tech tokenizers for German, Dutch, or Norwegian:
a. Click the Standard tokenizer.
b. Clear the German, Dutch, or Norwegian disagglutiner option.
7. Click Apply.
8. Reindex.
Enable Lemmatization with Basis Tech
With Exalead CloudView’s native tokenization, we only index the original words. At query time this adds an OR expansion for lemmatization.
For example: q=alsacien is expanded to q=alsacien OR alsacienne OR alsaciens OR alsaciennes.
When using BasisTech to tokenize a language, you must index the lemmatized form of the word in addition to the original form. Indeed, Basis Tech does not include the resource that associates a form to all its expansions.
1. In Data Processing > Semantic Processors, add a Lemmatizer semantic processor to your analysis pipeline.
3. Click your tokenization config (for example, tok0).
4. On the Advanced tab, add the following tag and matching mode:
a. Tag: lemma
b. Matching Mode: 2
5. Click Apply.
6. Reindex.
All lemma semantic annotations, which store the lemmatized form of the token, are indexed with a kind=2, meaning they are indexed in the same way as the original normalized form.
About Creating Additional Tokenization Configurations
A tokenization configuration specifies which tokenizers to use when Exalead CloudView analyzes incoming documents at index-time. It also specifies how to tokenize queries at search-time.
By default, Exalead CloudView uses tok0 as the tokenization configuration for converting text into tokens. However, if you create additional tokenization configs, you must specify them explicitly in Data Model > Semantic Types and Data Processing.
When do you Need to Create a New Tokenization
You may want to create a new tokenization config to define:
• A certain character as a separator, or a character as NOT being a separator. See Character Overrides.
• A specific pattern to be a word only, instead of a word with separators. For example, to make sure C++ is always indexed as the token C++. See Pattern Overrides.
Specify a tokenization config for a specific index mapping or semantic type, when you know that a certain meta contains characters that need to be interpreted differently than other alphanumeric metas. Typical examples are identifiers like user IDs, model numbers and product codes.
Index-Time and Search-Time Tokenization
When you specify a new tokenization config for document analysis at index-time, you must also specify this same tokenization config for interpreting queries at search-time.
You can specify a default tokenization config for a search logic, as well as an "exception" tokenization config for specific prefix handlers. For more information, see Specify a Tokenization Configuration for Prefix Handlers.
Indexing is both morphological and ngram-based. This gives Exalead CloudView a kind of fallback mechanism. For example, "cjk" (that is, Chinese Japanese Korean) in Linguistics > Tokenizations > Advanced > Form indexing triggers the indexing of isolated characters but we still index words made of several characters output by tokenizers. This way, in case of different tokenizations between indexing and querying for the same text (either because of a different context or because of a tokenization error), we can still find documents containing the sequence of characters.
Which Tokenization Config takes Precedence?
A tokenization config that is defined for a specific:
• semantic type overrides the one defined for its corresponding analysis pipeline.
• meta mapping overrides the one defined for its corresponding semantic type.
For example:
• The analysis pipeline ap0 uses the default tok0 tokenization config. Any text that is processed by processors added directly to this analysis pipeline is tokenized with tok0.
• The text semantic type uses tok1, and the text, location, and product_name metas in the data model are set up to use this semantic type. In other words, tok1 overrides tok0 for these three metas.
• However, the product_name meta has special tokenization requirements, so its index mapping only uses a third config, tok2, which overrides tok1.
Customizing the Tokenization Config
You can modify the default tokenization config, or create additional ones.
Create or Edit a Tokenization Config
1. In the Administration Console, go to Index > Linguistics > Tokenizations.
◦ Click an existing tokenization config to edit.
◦ Click Add tokenization config to create a new one.
Specify Another Tokenization Config for an Analysis Pipeline
1. In the Administration Console, go to Index > Analysis, then select your analysis pipeline (for example, ap0).
2. From the Tokenization config list, select a different configuration.
3. Click Apply.
4. Reindex your data.
This tokenization config is only used on metas processed by document or semantic processors that were manually configured in the analysis pipeline.
Specify Another Tokenization Config in the Data Model
1. In the Administration Console, go to Index > Data Model > Semantic Types tab.
2. Expand the semantic type you want to modify, or create a new one.
3. In the semantic type:
a. Make sure that the Tokenize option is selected.
b. From the Tokenization config list, select a different configuration.
4. Click Apply.
5. Reindex your data.
All properties using this semantic type tokenize the corresponding meta using this tokenization configuration, regardless of the tokenization config specified for its associated analysis meta.
Specify Another Tokenization Config for an Index Mapping
1. In the Administration Console, go to Index > Data processing, then select your analysis pipeline (for example, ap0).
2. Select the Mappings tab.
3. Under the Mapping sources list, click the mapping you want to modify.
4. From the Tokenization config list, select a different configuration.
Note: If this mapping was produced by a data model, you need to click Customize before you can modify any mapping settings.
5. Click Apply.
6. Reindex your data.
The meta for this mapping is always be tokenized using the tokenization config specified here, regardless of the tokenization config specified for its analysis pipeline or for its semantic type (if any).
About Decompounding
Decompounding is splitting up a word into components so that when searching for one of these components, the whole compound is found. For instance, we want "Lastwagen" or "Fahrer" to match "Lastwagenfahrer".
To achieve this, Exalead CloudView splits compound words into at most two components using a dictionary. Three issues may occur during the process:
• Since the dictionary cannot cover the integrality of a language (very specific/technical words may not be known from the algorithm), the compound may not be split because its components are not found in the dictionary.
• When there are more than one way to split the word, the most likely one is selected but this may not be the expected one.
• Some compound words should not be decompounded. The algorithm uses statistics to figure it out but some words may end up decompounded though it doesn't make much sense ("Handschu", "Volkswagen").
In these cases, the user can enrich the dictionary with his own rules by defining a list of words which should not be decompounded and a list of explicit decompoundings taking precedence over the Exalead CloudView-provided resource.
Custom Resource Creation
The user dictionary is a UTF-8 text file (user.txt) in the directory KITDIR/resource/all-arch/subtokenizer/ID where KITDIR is the root of CloudView unzipped kit directory and ID is one of following language identifiers: de (german), nl (dutch), no (norwegian).
The file format must be as follows (lines failing to match this format are ignored):
• Lines starting with # are comments (ignored)
• Lines containing one word define uncompoundable words
• Lines containing three words explicitly define how the 1st word of the line must be decompounded into the 2nd and the 3rd words
Note that words are matched case-insensitively but accents matter ("Kuchen" is not "Küchen").
# this is an ignored comment # this line states that Volkswagen shouldn't be split: volkswagen # this line forces decompounding of Lastwagenfahrer into Lastwagen+Fahrer: lastwagenfahrer lastwagen fahrer
Applying Changes
When you specify a new tokenization config for document analysis at index-time, you must also specify the same tokenization config for interpreting queries at search-time.
After editing the user dictionary:
• the indexingserver and the searchserver must be restarted for the modifications to be taken into account
• documents have to be reindexed
If issues should appear, turn the logging level of the indexingserver to debug and restart it. Search for [subtokenizer] in the logs to filter relevant lines.