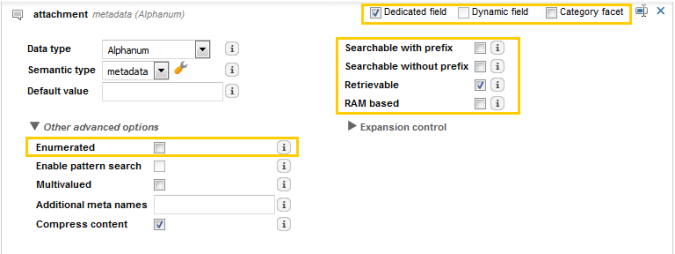
Property option | What it does | Impacts | Explanation |
|---|---|---|---|
Dedicated field | Creates an index field on disk. | Disk, and eventually search latency | The more index fields, the more folders on disk (where an index field = a folder), which in turns means more things to compact, and more things to replicate which in turn increases search latency. |
Searchable with prefix | Creates the inverted list, which is the lookup structure used to respond to search queries. | RAM | This also adds folders/files to disk, and at run-time, even when there are no queries sent to it, it consumes some RAM. The files containing the inverted lists is mapped by the index. Map files can be loaded or unloaded in RAM by the OS; this explains why virtual memory in the monitoring console may display as higher than available memory. |
Searchable without prefix | Copies the meta values into the text field. Typically used for legacy reasons (in v5). By default, the text field is targeted by the text prefix handler, and means that if users enter a query without a prefix, the search targets this text field. If you change the default prefix handler, however, it renders this option useless. In that case, it is better to use the renameContext doc processor and rename your meta to the name of the field targeted by your default prefix handler. | RAM Disk | Virtually the same RAM consumption as for Searchable with prefix. Less disk consumption as values are all stored in the same field. |
Retrievable | Copies the entire meta source in the attributes structure. This is the structure used for returning the meta values, whether this appears in search results, facets, or for sorting. Note: If you select this option without selecting "index field", the meta values are stored in the "metas" default attribute. | For search only: Disk. For faceting and search: RAM, since these must be RAM-based. | For faceting and sorting, the property must be both retrievable and RAM-based. This is because we need to ask for this value very frequently when sorting and faceting for the entire result set. Conversely, metas used only for search result display must be stored as retrievable, which means they are stored on disk. |
RAM-based | This only displays if "retrievable" and "index field" are selected. Important: Only use RAM-based for fields required for sorting, grouping, facet aggregations, or search-time facets. | RAM | The more fields that are RAM-based, the more memory consumed. There is a fixed amount of RAM consumed for each document, regardless whether this property is present or not. Sometimes for numerical properties, the default 64-bit allocated for this property is too much; if you only have a small range of values, you can reduce this value and thereby reduce memory consumption. |
Category facet | Selecting this means the original value of my meta is stored in the category field of the index. This was the only method to create facets in v5. However, in v6 there are very few reasons to use this because we can now create search-time facets for numerical, geographic, and date metas. Important: Only select this option when you want, for example, to facet on colors (red, blue, green, etc.), and do NOT need to use full-text search options (wild cards, approximate). You can, however, use this to do exact search, for example color: red returns all documents with the value red. | RAM Faceting (synthesis) speed | To process category facets efficiently, we have implemented a structure (cdict) to store these in RAM, which assigns an ID to each value. Having too many distinct values in a category field increases with ID range and impact memory consumption and the speed of faceting. |
Enumerated (Value facet) | Only available on alphanumeric properties with the index field option selected. | RAM and CPU, but less than for category facets | Since it does not manage hierarchical values, it does not perform the calculations required for parent-child relationships, and so consumes less RAM and CPU than a category facet. |