You can set up Exalead CloudView to broaden the scope of a user query, which is known as query expansion.
For example, you can expand queries to include synonyms, so when a user searches for dba, Exalead CloudView searches for dba OR "database administrator" OR "db admin". If phonetic query expansion is enabled, the query "exaleed" would expand to "exaleed" OR "exalead".
Query expansion does the following:
• enriches the query, using synonyms and semantics
• interprets and normalizes the query, such as by recognizing city names or acronyms.
Query expansion is configured on prefix handlers as targeting specific index fields is useful to make consistent query expansions. For example, while it makes sense to use synonyms when searching the title index field with the title: prefix handler, it does not when searching on the author index field with the author: prefix handler.
When Exalead CloudView parses a query written in UQL, it is represented as a structured query tree, where the inner nodes are query operators and the leaves are Boolean predicates.
Query expansion generates a new, larger query tree by processing query expansion modules. This is known as the query rewriting step.
Query expansion modules process the query tree to:
• enrich it, for example, by using synonyms and semantics,
• interpret and normalize it, for example, by recognizing city names or acronyms.
In the end, the query expansion generates a new query tree. This is the query rewriting step.
Note: After this step, all Leaf and Rex nodes in the tree have been converted to FinalLeaf nodes.
Query Expansion Example
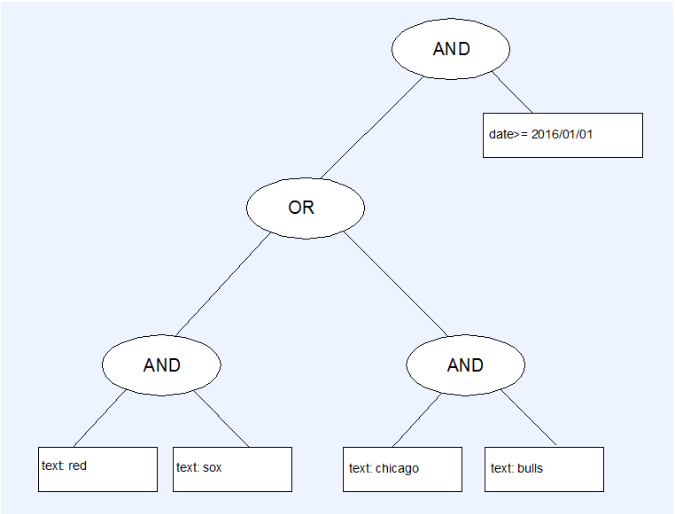
The figure below shows the query tree for a user’s search for documents containing the words "Red Sox" or "Chicago bulls", and modified after January 1, 2016:
((Red Sox) OR (Chicago Bulls)) AND lastmodified>=2016/01/01
Figure 12. The Default Operator between Two Text Predicates (like "Red" and "Sox") is a Boolean AND.
Character Interpretation
Leaf nodes can have different prefixes such as:
Character
UQL interpretation
-
Excludes terms if - is at the beginning of a leaf.
The leaf is interpreted as a NOT context.
For example, Sarbanes-Oxley is considered as a single leaf, while Sarbanes -Oxley is considered as two leaves, one of which is negated.
+
The leaf is treated as exact, which disables some expansion operations.
., &, -,
and other word separators
interpreted as a NEXT operator instead of an AND, when used to separate words without additional white spaces.
For example, ASP.NET is parsed as ASP NEXT NET instead of ASP AND NET.
The query processor allows nonalphanumerical characters in words in a few special cases that you can configure.
Leaves can also have options. You must specify the options in brackets and separated by quotes.
The following leaf options are available:
• query rewrite options, which modify the way the query processor works and expands the leaf.
• raw options, which are passed to the index.
Matching Modes
Each word can exist in the index at several matching modes (or index kinds). The matching between word predicates and document words is defined by the matching mode of predicates. The matching mode can be one of the following:
• Exact match: Matches only if the words match exactly. For example, The only matches with The. This is known as kind 0 (or k=0).
• Case-insensitive or Lowercase match: Ignores case for matching. For example, the and The match. This is known as kind 1 (or k=1). This level can be specified by the "i" option in UQL.
• Normalized match: Ignores case and accents, for example the, thé and Thé match. This is known as kind 2 (or k=2). This is the default matching mode but it can be changed using predicate options.
Note: You can specify other matching modes in Linguistics > Advanced > Form indexing.
Query Expansion Features
Query expansion features are described below.
Query expansion modules allow you to define semantic query expansions to perform on prefix handlers. For example, if lemmatization was configured on the title prefix handler, and the user enters the query title:(mouse and man), the query expands to title:((mouse OR mice) and (man OR men)).
Wildcard search is a pattern-matching feature enabled by default. It allows you to find documents that include "test", "tests" and "tesselation" when searching on "tes*". Additional configuration is available to fine-tune your results.
Wildcard search is expanded using a dictionary generated from the corpus. See Configuring Dictionaries.
Spellcheck can be enabled to suggest alternate spellings for words in the query. Spell-check is much more effective if you first extract spell-check ngrams at index-time.
When you install Exalead CloudView, most query expansion modules are already activated, with the exception of Synonyms, or the Custom query expansion module.
By default, these modules are set up for all supported languages. You can, however, choose to add multiple instances of a query expansion module (for example, several lemmatization modules) that are set up for different languages.
However, if you want a certain prefix handler to use a query expansion module, you still need to configure that prefix handler’s query expansion accordingly.
To enable query expansion you need to do the following:
• Activate query expansion modules: these are global processing units that must be defined for each search logic. They define the static parameters for the type of expansion. For example with synonym expansion, you must create a synonym dictionary, known as a resource file, for the synonym module.
• In the prefix handler, define which modules to use for query expansion: this is defined in the Query expansion config for the prefix handler.
Activate a query expansion module
1. In the Administration Console, go to Search > Search Logics > Query Expansion.
2. Under Query expansion modules, click Add module if the module you want to activate does not already appear on the list.
3. (Optional, except for Synonyms) Specify a resource file for the module. To define and compile a synonym resource file, see Synonyms.
4. Click Save.
You must now associate this module with one or more prefix handlers as described in the following procedure.
Set up a prefix handler to use a query expansion module
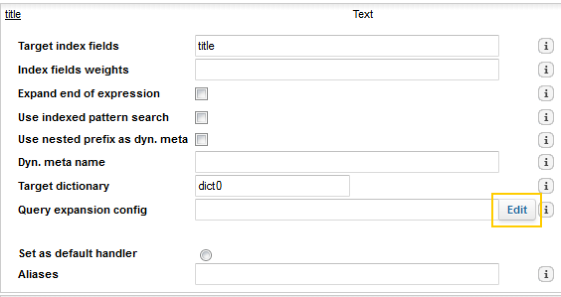
1. Go to the Query language tab and click the prefix handler that will use this module.
2. In the expanded view of this prefix handler, click Edit beside Query expansion config.
3. In the Query expansion config dialog, specify the semantic expansion for this prefix handler.
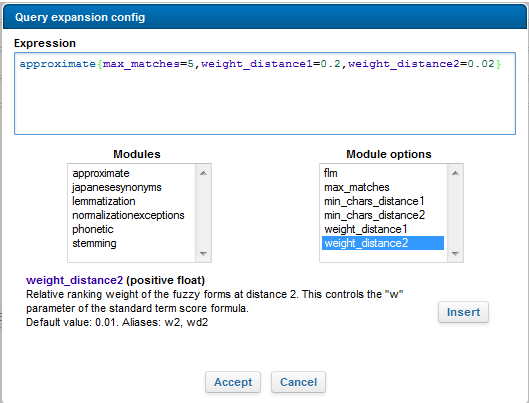
You can also dynamic parameters for the expansion. In the following example, the expansion expression uses the approximate query expansion module, and includes specific options that define the maximum number of matches and their relative importance.
For descriptions of the options available for each query expansion module, see:
Stemming expansion allows you to search for words with a common root, or stem.
For example, searching on the word "Britannia" would expand the query to include words with the stem "Britann", such as "Britannic" and "Britanny".
There is often some confusion in understanding the difference between stemming and lemmatization. Both have an objective of finding a common base for query words with several related derivations or inflected forms.
Dependencies
For stemming to work at search-time, you must first create stemmed forms at indexing time. For details, see Snowball Stemmer.
Stemming vs Lemmatization
Stemming is the simpler method, as it seeks to find the root (the stem) of a word by cutting off endings. For example:
• Searching on alsaciennes (women from the Alsace region of France) would also search for words with the stem alsac.
• Searching on alsace would also search for words with the stem alsac.
By contrast, lemmatization uses a more complex morphological analysis to find the singular or masculine form of nouns and adjectives.
• Searching on alsaciennes also searches for words with the lemma alsacien.
• Searching on alsace also searches for words with the lemma alsace.
• Moreover, searching on geese would also search for goose.
Stemming Rules
Depending on the language, two kinds of rule dictionaries are used:
• Rules based on the "Snowball" library.
• Internal CloudView rules
For stemming to work, the words must have been extracted from text at indexing time (this is the default configuration).
Stemming Options
When configuring a prefix handler’s query expansion, the following stemming options are available.
Option
Description
max_matches or m, or matches
Searches no more than N stems for a word. If the number of available stems exceeds this value, Exalead CloudView searches the N most frequent stems in the corpus. The default value is 10.
weight or w
Relative ranking weight of the stemmed forms. This controls the w parameter of the standard term score formulas. The default value is 0.1.
Lemmatization expansion allows you to search for the masculine or singular forms of feminine or plural nouns and adjectives.
For example, searching for geese would also search for the lemma goose.
There is often some confusion in understanding the difference between lemmatization and stemming. Both have an objective of finding a common base for query words with several related derivations or inflected forms. See Stemming vs Lemmatization.
Dependencies
For lemmatization to work at search-time, you must first create lemmatized forms at indexing time. For more information, see Lemmatizer
Languages Lemmatized Natively
Lemmatization is available in the following languages:
• English (en)
• French (fr)
• German (de)
• Italian (it)
• Portuguese (pt)
• Russian (ru)
• Spanish (es)
Languages Lemmatized with Basis Tech Add-On
If you want to perform lemma query expansion for languages tokenized by the Basis Tech (Extended Languages) tokenizer, you must configure the Lemmatizer semantic processor, as well as follow some additional steps for tokenization.
Looks up for the masculine form of a word when a feminine form is entered. For example, entering canadienne searches on canadien.
masculine_weight or mw
When transcribing a word from the feminine to masculine form, the resulting masculine form has this weight value instead of "w". The default value is 0.01.
Phonetization
Phonetic expansion allows you to search for alternative forms that sound like the original query. For example, searching for "exaleed" would also search for "exalead". This query expansion module works by default with the soundslike linguistic prefix handler.
Dependencies
For phonetization to work at search-time, you must first extract phonetic forms at indexing time. For more information, see Phonetizer.
Supported Languages
Phonetization is available natively for the following languages:
• Canadian (ca)
• Czech (cs)
• Danish (da)
• Dutch (nl)
• English (en)
• Estonian (et)
• Finnish (fi)
• French (fr)
• German (de)
• Italian (it)
• Norwegian (no)
• Portuguese (pt)
• Slovak (sk)
• Slovenian (sl)
• Spanish (es)
Phonetization Options
When configuring a prefix handler's query expansion, the following phonetization options are available.
Option
Description
max_matches or m, or matches
Searches no more than N phonetic forms for a word. If the number of available phonetic forms exceeds this value, Exalead CloudView searches the N most frequent forms in the corpus. The default value is 10.
weight or w
Relative ranking weight of the phonetic forms. This controls the w parameter of the standard term score formulas. The default value is 0.1.
Approximation expansion finds words that are lexicographically similar to other words. This query expansion module works by default with the spellslike linguistic prefix handler.
Approximation is useful for full-text search to correct user queries with typos. For example, if the user enters croped, the search results displays hits with cropped, the correct spelling, automatically.
Approximation is the search for a query word with a fuzzy match in the corpus. It is performed by calculating the Damereau-Levenshtein distance between the query word and the corpus word.
Approximation Vs Spell Check
Approximation is similar to spell check. The difference is that approximation only applies to the word that follows the prefix handler with which it is associated (myprefix: word). Meanwhile, spell check applies to the entire user query and has more configuration options.
The approximation module considers both the word length and the number of transformations allowed to expand the original query with additional words. Transformations mean that you replace (substitute) a letter, add a letter, transpose a letter, or delete a letter.
The approximation module searches for words that are at transformation distance 1 or 2 of the original word from the user’s query. Distances are hard-coded, so you can only control the word length that triggers distance 1 or distance 2. In other words, depending on the word length, you set either max_distance=0, 1 or 2.
When configuring a prefix handler’s query expansion, the following approximation options are available.
Note: The approximation module has default values for these options. To override them, you must define them explicitly in the query expansion config expression.
Approximation Options
Option
Description
flm
Specifies an additional transformation distance (think of it as a penalty) on any transformation on the first letter. This shows that in most cases, people do not make typos on the first letter.
For example, "abc" and "zbc" are at:
• distance 1 if flm=false,
• distance 2 if flm=true.
The default value is true.
max_matches or m or matches
Searches no more than N fuzzy matches for a word. If the number of available fuzzy forms exceeds this value, Exalead CloudView searches the N most frequent forms in the corpus.
The default value is 10.
min_chars_distance1 or mcd1
Only searches for distance 1 fuzzy matches if the original word in the query is at least N characters long.
This avoids too much approximation on very short words.
The default value is 5.
min_chars_distance2 or mcd2
Only searches for distance 2 fuzzy matches if the original word in the query is at least N characters long.
This avoids too much approximation on short words.
The default value is 10.
weight_distance1 or w1 or wd1
Relative ranking weight of the fuzzy matches at distance 1.
This controls the "w" parameter of the standard term score formula.
If the query expansion config expression is set to approximate{min_chars_distance1=5} only
• srewdriver => approximation works, there is 1 transformation (deletion of the "c" character).
• screwdrive => approximation works, there is 1 transformation (deletion of the last character "r").
• screwqdriver => approximation works, there is 1 transformation (insertion of the "q" character).
• scrwedriver => approximation works, there is 1 transformation (transposition of the "w" and "e" characters).
• screqdriver => approximation works, there is 1 transformation (substitution of the "w" character by the "q" character).
• sredriver => approximation does not work as there are 2 transformations (deletion of "c" and "w").
If we set the query expansion config expression to approximate{min_chars_distance1=,min_chars_distance2=10}
• sredriver => approximation still does not work because:
◦ there are 2 transformations (deletion of "c" and "w")
◦ and there are only 9 characters in the query word whereas the minimum number to get 2 transformations is set to 10.
If we set the query expansion config expression to approximate{min_chars_distance1=,min_chars_distance2=9}
• sredriver => approximation works because:
◦ there are 2 transformations (deletion of "c" and "w")
◦ and there is the minimum number of 9 characters to make these 2 transformations.
Example: Approximation for an Error on the First Letter
Let us say that we have created a prefix handler called approxprefix using the approximation module with its default option configuration.
We enter the query: approxprefix:correkt and get matches for documents containing the word correct. However, if we search for approxprefix:vorrect, we do not get any matches.
This behavior is normal, since in most cases, people do not make typos on the first letter. Therefore, there is an additional transformation distance by default for any transformation on the first letter (flm=true).
Since vorrect is a short word (fewer than 10 characters) and substituting "c" for the first letter "v" equals to a transformation distance of 2, the approximation module does not expand the search.
If we search for approxprefix:vorrection, the approximation module expands the search to include correction, as the search term is 10 characters long.
To disable the additional transformation distance for first letters, edit the query expansion config expression to include flm=false. In our example, we would have the following expression: approximate{flm=false}
We could also tackle this kind of issue by reducing the minimum length to trigger distance 1 and distance 2 (using the min_chars_distance1 and min_chars_distance2 options).
Normalization Exceptions
When the query includes a word that is subject to a normalization exception, it is not usually normalized. If the normalization exceptions module is present, the query is performed on both the normalized and the non-normalized form.
For example in French, "maïs" (corn) is subject to a normalization exception because it conflicts with "mais" (but).
• Without this semantic processor, a search for mais only searches for mais, and does not find maïs.
• With this semantic processor, a search for mais searches for (mais OR maïs).
Synonyms
The Synonym expansion module adds alternative forms to user queries. For example, if the text prefix handler uses the synonyms module, the query: "db architect" expands to "db architect" OR"data base architect" OR"database architect".
Unlike the other query expansion modules, you must first compile your own synonym dictionary, also known as a resource file, that defines the possible synonyms for a particular expression.
1. Create a synonym XML file containing the following code:
• true (default): synonym matching is punctuation sensitive.
• false: punctuation is ignored during matching. For example, the synonym "twenty-seven" matches "twenty seven".
stopwordsResource
Path to the compiled ontology containing stop words used at build time when generating permutations and stop word-free forms.
Default value is resource:///stopwords/ontology.bin.
Note: Exalead CloudView only provides French and English stop words.
You can use your own stop word resource by building an ontology containing a package exalead.stop and the list of forms for each language you want to support:
<Ontology xmlns="exa:com.exalead.mot.components.ontology" matchOnSeparators="true"> <!-- this stopword list is used by the synonym compiler to generate stopword-free forms and permutations for english and french synonyms --> <Pkg path="exalead.stop"> <Entry lang="en"> <Form value="of" level="lowercase"/> <Form value="the" level="lowercase"/> <Form value="a" level="lowercase"/> ... <Entry> <Entry lang="fr"> <Form value="de" level="lowercase"/> <Form value="du" level="lowercase"/> <Form value="la" level="lowercase"/> ... <Entry> </Pkg> </Ontology>
permutations
Possible values:
• true: For each synonym, extra forms made of word permutations are added. Before computing permutations, stop words are removed. For example, the synonym "lyrics of the song" matches "song lyrics".
• false (default): Word permutations are not added.
addStopwordFreeForms
Possible values:
• true: For each synonym, an extra form (from which stop words have been removed) is added.
• false (default): Extra forms are not added.
originalExpr
expression specified by the user
alternativeExpr
Expressions that are matched to the originalExpr.
equivalenceClass
Possible values:
• true, synonym searching works in both directions: queries using originalExpr return documents including alternativeExpr, and vice versa.
• SynonymToSynonymSet, when you search for one of the alternativeExpr expressions, the query also expands with the originalExpr.
• SynonymSetToSynonym (or false, kept for backward compatibility), when you search for the originalExpr, the query is expanded respecting the alternativeExpr order.
You can activate the Japanese synonyms module to get a good support of synonyms in Japanese.
When configuring a prefix handler’s query expansion, the following Japanese synonym options are available.
Option
Description
max_distance or md
Maximum distance allowed for synonyms expansion. This limits the query expansion to synonyms within the specified distance.
max_expansions or me
Maximum number of synonyms to expand for a query word. For example, if you set this option to 5, only the first five synonyms serve for the query expansion.