This section explains how to manage semantic annotation with the Annotation Manager or with custom code.
Manage Annotations with the Annotation Manager
The Annotation Manager allows you to perform several operations on annotations under the right conditions. You can use it to copy, select, and remove annotations.
The Annotation Manager configuration consists of a list of operations.
Important: There is no define order of the execution of operations. If you really care about operation ordering, you must add several annotation managers to the semantic pipe.
Copy Annotation
You can copy a source annotation along with its display form, display kind, and trust level to a target annotation.
Option
Example
Copy without condition
For example, to ignore the distinction between famous and nonfamous people.
An ontology matcher upstream or any other semantic processor can set the annotation blocklist.person. Both annotations must start and end exactly on the same tokens.
Remove an annotation if the annotated text span and display form match those of another one
For example, we want to implement a block list with a fine granularity:
... the annotation is removed if the annotation (blocklist.title, "professor") occurs at the very same place, thus block listing the specific approximation.
Keep the first occurrence of an annotation and remove all others
For example, to keep only the first organization occurrence in title and text:
If there are more than 5 most frequent places, the resulting list is arbitrarily truncated since truncate="true" guarantees that no more than 5 annotations are ever reported.
Select the most frequent annotation in a document among a list
The most frequent annotation is used to output a selectedAnnotation document annotation whose value is one of the annotations from the list.
Select annotations depending on an index field (context) priority
For example, we want to select an annotation from the "title, text" contexts, by first looking within the title context and then, if the annotation is not found, looking within the text context:
In most semantic-oriented projects, you need to manipulate (filter, combine, replace, etc.) the semantic annotations set by your semantic processors before sending them to the index.
The easiest way to do this is to add semantic processors into the Document Processor pipeline, transforming the annotations into metas (also known as chunks). Then you can manipulate them using either:
• custom java code via the JavaDocumentProcessor
• standard document processors such ReplaceValues or ConcatenateValues.
Example: Index Term Occurrences in a Document
Let us say you want to send to the index the number of times a term is matched in the document from an existing list of terms.
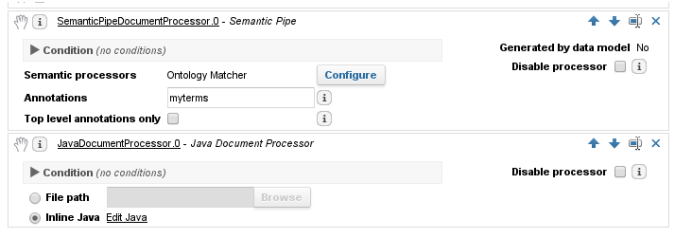
Recommendation: Use the OntologyMatcher to detect all terms. Go through it using a SemanticPipeDocumentProcessor. Convert the semantic annotations into metas (or chunks) and use custom java code to count them.
Create a List of Terms
This ontology annotates each term of the list with the "myterms" annotation.
Add the following configuration to the end of your document processor Analysis Pipeline.
Each "myterms" semantic annotation is converted into a meta (or chunk), that the Document Processors can manipulate.
The XML representation of the SemanticPipeDocumentProcessor configuration looks like:
<SemanticPipeDocumentProcessor annotations="myterms" // Comma-separated semantic annotations that will be converted into metas topLevelAnnotationsOnly="false" // only convert document annotations? disabled="false" name="SemanticPipeDocumentProcessor.0"> <OntologyMatcher resourceDir="/path/to/myterms.bin" disabled="false" name="OntologyMatcher.0"/> </SemanticPipeDocumentProcessor>
In the JavaDocumentProcessor, count the number of metas (or chunks) named "myterms". Add the count to a new "nbTerms" meta (the mapping of this "nbTerms" meta to the index is not detailed here).