Troubleshooting Document Analysis
Below is a list of potential issues with document analysis and their solutions.
Identify the Cause of the Index Crash
The following procedure describes how to identify the cause of the crash.
1. Go to the log.log file in <DATADIR>\run\indexingserver-bg0\
2. Look for ‘ERROR’ .
3. You need to locate:
◦
◦
◦
The document URI is added to the block list file indexing_uri_blacklist.txt in <DATADIR>\gct . It is not indexed anymore.
4. Contact support for advanced analysis (file format, character strings etc.).
Example:
@@CRITICAL ERROR with "/%2Fdata%2Fcorpus%2Fdepeches%2Fvrac%2Ffr/3_2006-06-21T1226_FAP4251.txt"
Key elements are:
• 3_2006-06-21T1226_FAP4251.txt
• LanguageDetector
• process
Unexpected Search Behavior
Search for Issues in Document Processing
Follow the steps below to identify document processor issues.
Step 1 - to Add log Information
To display detailed chunks in the log.log file, you must first add a Debug Processor element to your document processors list.
1. From the Administration Console , go to Index > Data processing > Pipeline name .
2. In the Document Processors tab, click Other in the Processor types menu.
3. Drag the Debug Processor element to the end of the processors list.
Example: <Debug> tags are displayed:
[2013/09/23-09:54:11.584] [info] [AnalyzerThread-bg0-default_model-1] [analysis.debug] uri:
Step 2 - to Submit Document Using cvdebug
1. Submit your document to test processors in your pipeline:
cvconsole cvdebug> analysis analyze path=<PATH_TO_DOCUMENT>
For example, submit a .CSV file.
cvconsole cvdebug> analysis analyze path=/tests/myfile.csv
The output is a mapping of contexts and chunk values.
<TestAnalysisPipelineOutput xmlns="com.exalead.indexing.analysis.v10" documentProcessorsTimeUS=1000
Search for Issues in Semantic Processor
You can follow the steps below to identify semantic processor issues.
Step 1 - Display Semantic Processors for Each Document
To display detailed information on semantic processing in an HTML file, you must first add a Debug Processor element to your semantic processors list.
Important: The HTML output is verbose. You can use sample data to avoid using large amounts of disk space during indexing.
1. From the Administration Console , go to Index > Data processing > Pipeline name .
2. In the Semantic Processors tab, drag the Debug Processor to the end of the processors list.
3. In the Input from field, specify the HTML file in which information is logged.
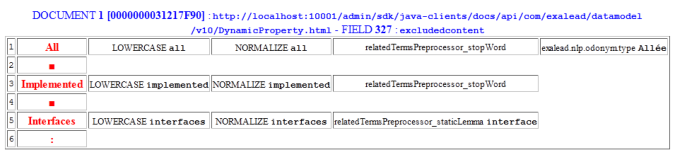
Example: all semantic processing applied to field 327 of document [0000000031217F90]
Step 2 - Submit Text or Document
1. Submit text through the semantic pipeline to display all running processors:
◦
cvconsole cvdebug> semantic annotate language=en context=text value=”WORD”
◦
cvconsole cvdebug> semantic annotate-file language=en path=<PATH_TO_TXT_FILE>
Example: submit the word ‘test’
cvconsole cvdebug> semantic annotate language=en context=text value=”test”
The output displays tokens tagged with annotations:
<AnnotatedToken id="0" kind="TOKEN_SEP_PUNCT" lang="en" token="ΓÇ¥" offset="0" />
Step 3 - Display All Processors
1. Display the list of semantic processors in the analysis pipeline using cvdebug :
cvconsole cvdebug> semantic dump-pipe
The output (extract) displays each semantic processor and resources:
<Processor>
This site works best with JavaScript enabled